Please note: I am currently rebuilding this app: the URLs below will not work.
I built a prototype API and application for searching Google developer video transcripts and metadata:
shearch.me?q=webrtc
simpl.info/s

Why?
1. I work for a search company.
2. More and more content online is video.
3. Video is inherently opaque to textual search.
How can we navigate and search media content? Not least the thousands of videos on Google Developers, Android Developers and Chrome Developers.
Thankfully Google has a secret weapon: a crack team of transcribers who produce highly accurate, timecoded captions for Google videos. (Not to be confused with the sometimes slightly surreal automated alternative.)
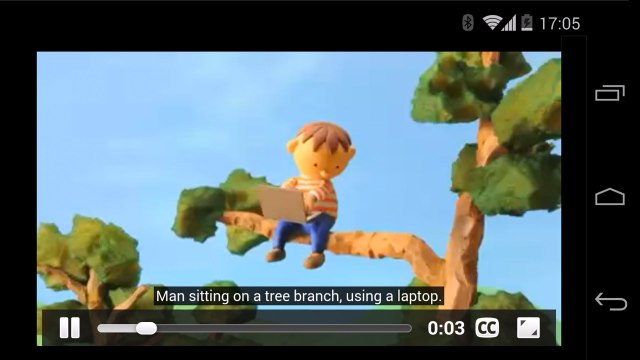
Some people prefer to access information by reading text rather than watching videos, so I also enabled access to downloadable transcripts:
simpl.info/s?t=ngBy0H_q-GY
The transcripts have Google Translate built in, so you can choose read them in a different language. Caption highlighting is synchronised with video playback — and you can tap or click on any part of a transcript to navigate through the video.

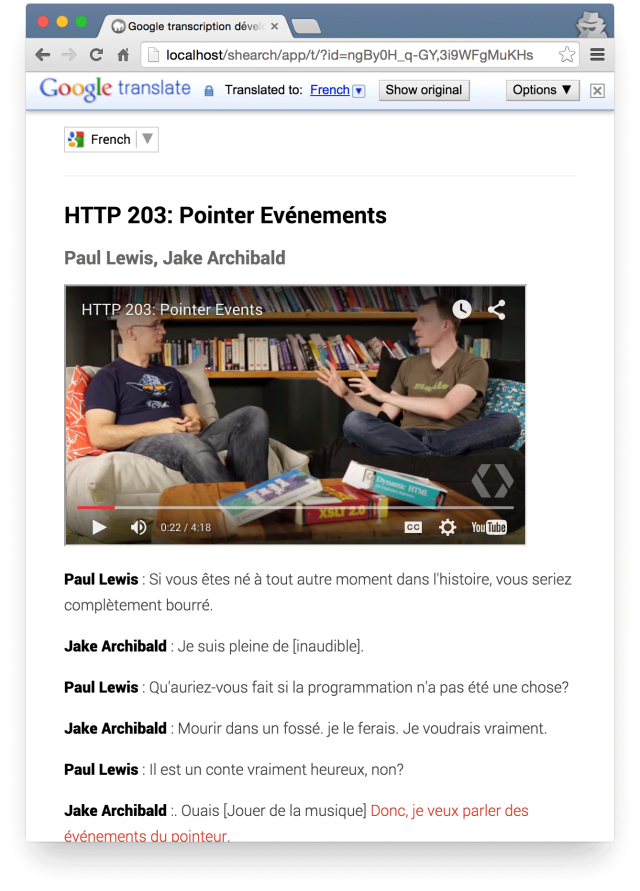
(Apologies if the translation is dodgy…)
I hope the app and API are useful. As ever, your feedback would be much appreciated.
With some minor tweaking you could use my app and API to build search for any YouTube channels that have manually captioned videos — just tweak the channels in the code.
A quick hat-tip to the world’s transcribers, captioners and reporters.
These unsung heroes have amazing, hard-won skills! If you’ve ever seen a captioner at work at a live event, you’ll understand what a complex and difficult job it is.
Why are captions important? Because they give more people better access to media: those of us with impaired hearing, or whose first language isn’t the language of the video we’re watching.
Likewise, respect is due to the archivists who catalogue video after broadcast — the art of ‘shotlisting’. Without shotlists, history is lost (and it’s hard to resell footage…) Where was that sequence of Donald Rumsfeld getting down with Saddam Hussein? Shotlisters work long days faithfully cataloguing and timecoding news stories, often at double speed, one package (or rush) after another. One of my ex-colleagues at ITN, Jude Cowan, wrote a brilliant and moving book of poetry on the subject.
Examples
Search for something:
simpl.info/s
Transcripts for two or more videos:
simpl.info/s/t?id=ngBy0H_q-GY,3i9WFgMuKHs
Link to a query:
simpl.info/s?q=breakpoint
Data and transcript for a video:
shearch.me/2UKPRbrw3Kk
Transcript only:
shearch.me/t/2UKPRbrw3Kk or
shearch.me/transcript/2UKPRbrw3Kk or
shearch.me/captions/2UKPRbrw3Kk
Multiple values — comma, semicolon or pipe delimiter, spaces OK:
shearch.me/2UKPRbrw3Kk,iZZdhTUP5qg
shearch.me/t/2UKPRbrw3Kk, iZZdhTUP5qg
Search any field for a query, spaces OK — can be a bit slow:
shearch.me?q=http 203
More shortcuts: c for captions, s for speaker — speakers are parsed from transcript:
shearch.me?c=svg&s=alex
Can specify ranges for commentCount, dislikeCount, favoriteCount, likeCount, viewCount:
shearch.me?speaker=Jake&viewCount>10000
You can use any of these values to specify order:
shearch.me?speaker=Jake&viewCount>10000&sort=viewCount
Add a hyphen for descending order:
shearch.me?speaker=Jake&viewCount>10000&sort=-viewCount
Show items with titles that include ‘Android’
shearch.me?title=Android or
shearch.me?t=Android
Items with speakers that include Reto and a title that includes Android:
shearch.me?title=Android&speakers=Reto
shearch.me?t=Android&s=Reto
Spaces are OK:
shearch.me?speakers=Reto Meier&title=Android
More complex stuff works too:
shearch.me?(title=Android Wear|description=Android Wear)&speakers=Reto
shearch.me?(title=Android Wear|description=Android Wear)&speakers=[Reto,Wayne]
shearch.me?title=”Android Wear”|title=WebRTC
shearch.me?(title=Android Wear|description=Android Wear)&speakers=Timothy
Fuzzy matching — with apologies to Wayne, whose name I generally misspell :):
shearch.me?speakers=pekarsky~
For dates, use ‘from’ and ‘to’, which can cope with anything Date can handle:
shearch.me?from=Feb // assumes text-only is a month this year
shearch.me?from=April 2014
shearch.me?from=2013-03-01&to=2013-05-01
shearch.me?from=2013&to=2014 // midnight, 1 January to midnight, 1 January
Get total for any quantity field — this query returns the total number of views for all videos:
shearch.me?count=views
Get total for any query and quantity field:
shearch.me?speakers=butcher&count=views
Get all individual values for any quantity field for all videos — returns an object keyed by amounts, values are number of occurrences for each amount:
shearch.me?countall=views
Get all individual values for any quantity field for any query:
shearch.me?speakers=reto&countall=views
Build a chart from results (views for videos that mention ‘Chrome’):
simpl.info/s/chart.html
The code
Available from GitHub: github.com/GoogleChrome/dev-video-search.
Truth be told, it’s a bit of a dog’s dinner. I wrote most of the app and API on long flights and in the small hours under the influence of jet lag. E&OE! The JavaScript is a little… procedural, and I hereby pledge that I will mend my ways.
Issues and pull requests welcome.
There are three code directories:
app: the web client (as used at simpl.info/s). This will automatically choose the local Node middle layer (below) if run from localhost.
get: middle layer Node app to get data from the database. For testing, you can run this locally with the app running from localhost. I run the live version on Nodejitsu at shearch.me, for queries like this: shearch.me?captions=svg&speaker=alex (same as shearch.me?c=svg&s=alex).
put: Node app to get YouTube data and transcripts, massage the response and put it in a CouchDB database at cloudant.com.
FAQs
Why didn’t you use Node on Google?
I’d like to, but Nodejitsu is very easy:
$ npm install jitsu
$ jitsu login
$ jitsu deploy
$ 🙂
Why didn’t you use Firebase?
I used Cloudant, which has Lucene search built in (and is based on CouchDB, and is very easy to use). Firebase can now be used with Elasticsearch, but when I started that required extra installation.
Why didn’t you just use MySQL or …
I probably should have. In fact, an SQL database with Lucene for full text search might have been much more appropriate than CouchDB. (This kind of search is actually much easier with Firebase now.)
How was CouchDB?
Good in some ways, and quick. In particular, the JSON/HTTP/REST styles feels fits well with Node/JavaScript development.
Problems came with full text search:
• Full text search is not built into CouchDB, though it can be added on with Lucene or other search engines.
• CouchDB searches return entire documents, with no ‘partial’ results. (In my case, a document represents all data for a video.) So, for example, if I want to return only captions that include ‘Android Wear’, I need to retrieve all the documents (in their entirety) that have captions that mention ‘Android Wear’ then filter.
• CouchDB search queries cannot be combined: for example, ‘get me all videos from 2013 with WebRTC in the title’. So, again, you have to add your own filter.
How big is the database?
Around 250MB, but more like 150MB without transcripts: the transcript for each document is really just a convenience to make it quick and simple to retrieve human readable transcripts, and replicates the captions (with a few tweaks).
How often is the data updated?
At present I’m updating the database manually to avoid code changes breaking it, but once the code settles down I’ll run automatic updates every (say) 30 minutes.
Why didn’t you use io.js?
No big reason. Node.js has been around longer.
How many documents have transcripts?
Last time I looked: 4312 videos, 3550 with transcripts.
How did you get the speaker names?
With a bit of sneaky regexing these are parsed from transcripts.
NB: speaker names are not parsable for many captions, so speaker search results may not always be complete.
Why are caption matches returned as span elements?
The primary use for the caption matches is within HTML markup. Returning JSON for each span might be neater and less verbose, but for most apps that would entail extra effort transforming to HTML. I could be persuaded otherwise.
How long does it take to store and index data?
This depends a lot on connectivity. From work, the app gets and inserts the video data and transcripts in under three minutes. From home, it takes about 10 minutes.
Indexing takes about 10 minutes.
What build tools do you use?
I use JSCS and JSHint with grunt and githooks to force validation on commit.
Chrome JSON formatting extensions, pro.jsonlint.com and regex101.com were very useful.
TODO
- I haven’t written any unit tests – yet.
- Error handling is minimal.
- Code refactoring is in the pipeline.
- I don’t know a lot about working with sockets on Node, so a lot of the code has to be deliberately synchronous to avoid errors. I’m sure someone could help me…
- The shearch.me API is HTTP only as yet.
- Use the official YouTube Captions API.
- I wanted to use Firebase, but when I started it was a bit tricky to implement full-text search, so I opted for Cloudant. It’s now pretty simple to use Firebase with ElasticSearch, so I’ll port the data at some stage.
- Database updates are done manually at the moment — mostly because I’m worried about messing up the sample app. Easily automated.